Вы не задумывались, почему в финансовых отчетах данные представлены в том порядке, в каком они там есть? Элементы затрат, например, всегда начинаются с материалов, затем зарплата, аренда, амортизация и т.д. Статьи затрат также идут в своем порядке. Также детализация по городам: частый вариант по удалению от столицы или по численности населения.

Почему порядок именно такой? Удобно ли это для принятия решений? На самом деле – нет. В большинстве случаев данные эффективней располагать по убыванию оцениваемого показателя. Другая ситуация – вас могут попросить вывести не всех менеджеров, а только десятку лучших. И вам потребуется ранжировать данные, а затем отсортировать по ТОП-10. В Power Pivot и Power BI несколько способов, как это сделать. Один из них – специальная DAX-формула RANKX.
Расчет рейтингов с RANKX
Итак, задача: присвоить рейтинг в зависимости от величины показателя. Например, определить места менеджеров по сумме продаж за период. Для правильной работы RANKX потребуется справочник, для которого выполняется ранжирование. Поэтому чтобы присвоить рейтинги менеджерам, в модели данных должен быть справочник с ФИО. У нас в примере это таблица ‘менеджеры’. Пример вычислений с ранжированием по менеджерам:
продажи = SUM ( 'данные'[выручка] ) |
рейтинг = RANKX ( ALL ( 'менеджеры' ), [продажи] ) |
Добавим рейтинги в таблицу. Всё верно, но в итоговой строке появилась «лишняя» единица.
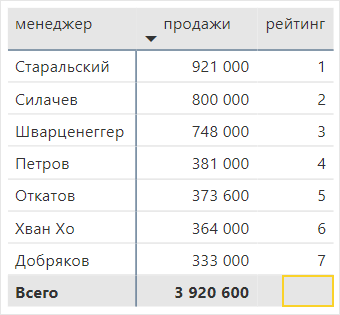
Поменяем формулу, чтобы в строке с итогами не выводились ненужные цифры. В Power BI для управления итоговой строкой используется формула ISINSCOPE. В Power Pivot в Excel такой формулы нет и там можно воспользоваться функцией ISFILTERED.
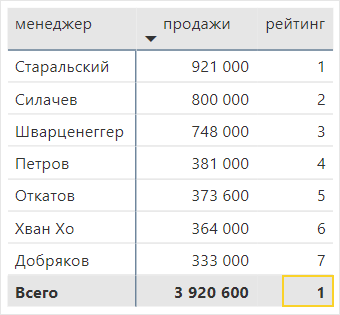
| рейтинг = IF ( ISINSCOPE ( 'менеджеры'[менеджер] ),RANKX ( ALL ( 'менеджеры' ), [продажи] )) |
Получилась таблица без цифр в итоговой строке. Рейтинги можно посмотреть за период или в динамике, например, на Bump chart – диаграмме изменений.
ALL или ALLSELECTED?
В предыдущем примере мы использовали формулу ALL, чтобы обратиться к справочнику менеджеров:
ALL ( 'менеджеры' )
Из-за этого рейтинг был посчитан по всем менеджерам компании, и он не зависит от того, каких менеджеров пользователи выбирают на срезах. Чтобы составить рейтинг с учётом примененных фильтров, лучше использовать формулу ALLSELECTED.
| рейтинг = IF ( ISINSCOPE ( 'менеджеры'[менеджер] ),RANKX ( ALLSELECTED ( 'менеджеры' ), [продажи] )) |
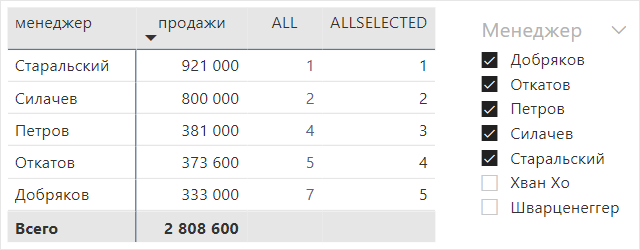
Какую формулу лучше выбрать? Если рейтинги не должны зависеть от фильтров, заданных пользователями, используйте ALL. Если рейтинги определяются по списку отфильтрованных значений – ALLSELECTED.
Синтаксис RANKX
Какие еще есть способы расчета рейтингов? Порядок ранжирования можно задать в самой формуле.
RANKX ( <таблица> , <выражение> [, <значение> [, <порядок> [, <ранг после одинаковых> ] ] ] ), где
| таблица | таблица с данными |
| выражение | выражение, рассчитывающее значения для ранжирования |
| необязательные: | |
| значение | добавляется к возможным значениям выражения, если такого значения нет |
| порядок | порядок ранжирования: ASC – по возрастанию, DESC – по убыванию |
| ранг после одинаковых | способ определения ранга, если есть одинаковые значения <выражения> — для одинаковых значений будет определен одинаковый ранг, а следующим присвоится: Skip – следующее значение ранга + количество предыдущих одинаковых значений Dense – следующий по порядку ранг. |
Необязательные части формулы можно пропустить, указав подряд несколько запятых: , , ,
- ASC или DESC определяет порядок ранжирования – по возрастанию или по убыванию.
рейтинг DESC = RANKX ( ALL ( 'менеджеры' ), [продажи], , DESC ) |
рейтинг ASC = RANKX ( ALL ( 'менеджеры' ), [продажи], , ASC ) |
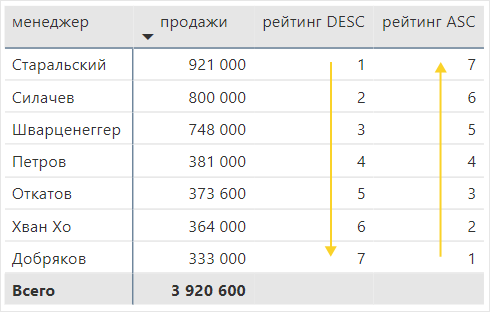
Если в формуле указать ASC, то у наименьшего показателя будет самый высокий рейтинг. Так удобно ранжировать дебиторскую задолженность – чем она меньше, тем лучше. Если выбрать DESC, то ранжирование будет от большего к меньшему.
- Dense и Skip нужны, чтобы определить ранг после появления одинаковых показателей.
В примере у некоторых менеджеров были одинаковые продажи, поэтому им присвоены одинаковые места. То, какое место займет следующий менеджер, будет зависеть от выбора Dense и Skip.
рейтинг Dense = RANKX ( ALL ( 'менеджеры' ), [продажи] , , , Dense ) |
рейтинг Skip = RANKX ( ALL ( 'менеджеры' ), [продажи] , , , Skip ) |
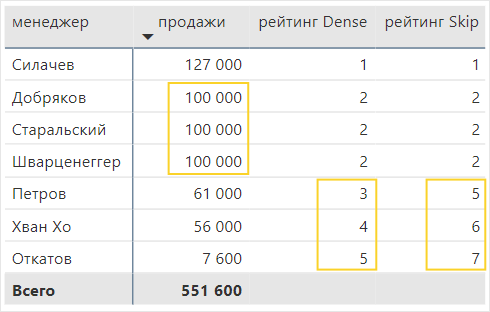
В случае с Dense для одинаковых значений будет определен одинаковый ранг. Для следующего значения ранг будет считаться последовательно, по порядку.
Если выбрать Skip, то у одинаковых значений тоже будет один ранг. А следующий ранг будет определяться так, чтобы общее число мест было равным количеству менеджеров.





